
nathan_H
K-means Clustering(평균 군집화) 본문
K-means 알고리즘.
k-means알고리즘 대표적인
분리형 군집화 알고리즘 가운데 하나이며,
말그래도 k개 평균으로 군집을 나눠주는 알고리즘이다.
각 개체는 가장 가까운 중심에 할당되며,
같은 중심에 할당된 개체들이 모여 하나의 군집을 형성한다.
그래서 k-means알고리즘 적용시
사용자가 사전에 군집 수를 정해야 한다.
K가 hyperparameter라는 이야기이다.
수식은 아래와 같다.
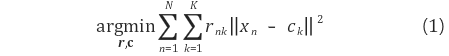
여기 rnk는 n번째 데이터가 k번째 cluster에 속하면 1,
아니면 0인 값을 가지는 binary variable이며,
ck는 k번쟤 cluster의 중심을 뜻한다.
즉 k-means clustering 을 실행한다는 것은
주어진 데이터 x에 대하여 rnk와 ck 값을
설정하는 것과 같다.
k-means의 표준 알고리즘.

위 그림은 sudo 코드로 작성한 k-means 알고리즘의 표준버전이다.
- Initialization: 초기 ck을 설정한다. 랜덤 초기화, Forgy 알고리즘, MacQueen 알고리즘 등 ck를 초기화하기 위한 다양한 알고리즘들이 제안되었으며, 가장 기본적인 알고리즘은 랜덤 초기화이다.
-
Assignment: [알고리즘 1]의 4~6번째 줄과 같이 모든 데이터에 대하여 가장 가까운 cluster를 선택한다. 데이터와 cluster간의 거리는 데이터 벡터 xn과 cluster의 중심 ck간의 거리로 계산된다.
-
Update: 모든 데이터에 대하여 가장 가까운 cluster가 선택되면, 이를 바탕으로 ck를 수정한다. 이 단계에서 ck는 [알고리즘 1]의 8~10번째 줄과 같이 k번째 cluster sk에 할당된 모든 데이터 벡터의 평균으로 갱신된다.
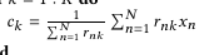
-> cluster centroid(무게 중심)
위에 표준 알고리즘을 쉬운 버전으로 해석을 한다면
1) 임의의 k개 cluster centrodid G1 ~ Gk 선택.
2) 각 데이터 di 와 G1 ~ Gk 에 대한 '거리' 계산하여,
가장 가까운 GI로 할당(예: Euclidean distance)
3) cluster centroid G1 ~ Gk 재계산(update)
4) 데이터가 할당된 cluster가 없을 경우 2) ~ 4) 반복.
example)
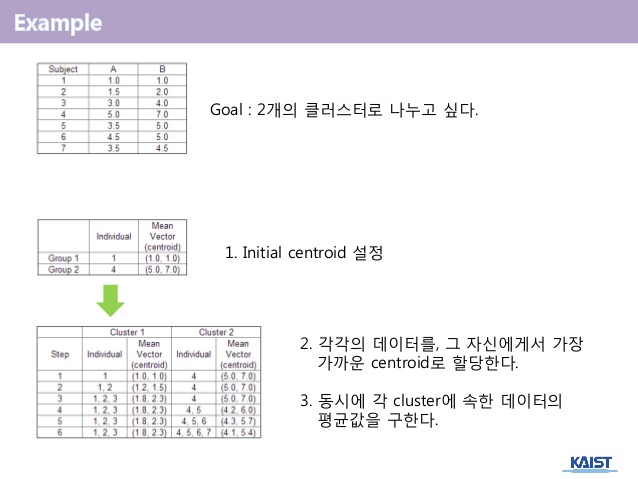
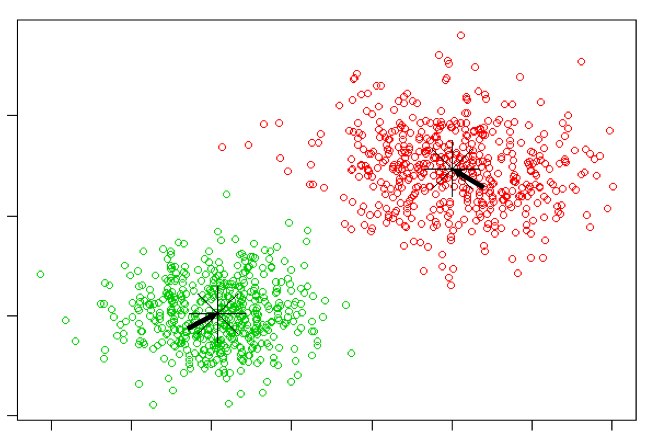
K-means와 EM 알고리즘.
위에서 볼수 있듯이
k-means는 EM알고리즘 기반으로 작동한다고 볼수도 있다.
EM알고리즘은 크게 Expectation 스텝과 Maximization 스텝으로 나뉘
이를 수렴할 때까지 반복하는 방식이다.
동시에 해를 찾기 어려운 문제를 풀 때 많이 사용되는 방법론입니다.
K-means의 경우
(1) 각 군집 중심의 위치
(2)각 개체가 어떤 군집에 속해야 하는지 멤버십,
이 두 가지를 동시에 찾아야 하기 때문에 EM 알고리즘을 적용할 수 있다.
- Expectation : 모든 개체들을 가장 가까운 중심에 군집으로 할당
- Maximization : 중심을 군집 경계에 맞게 업데이트.
- 반복.
K-means 특징과 단점
1) 최적의 cluster개수 선정.
최적의 cluster개수를 정하는 것은
관점에 따라 '최적'의 개념이 달라질 수 있다.
(어떤 feture에 중요도를 두느냐)
그래서 다양한 관점에 따라 해석되는 의미가 달라진다.
그래서 이를 결정하기 위해 나온 연구들이 많은데
- Hierarchical clustering 결과를 활용하여 최적의 개수 짐작.
Elblow method
->여러 후보 k값들에 대하여, cluster들의 적절함 평가
(예 : cluster 중심으로부터의 거리 등)
->Grid search : 여러 후보들에 대하여 일일이 실행해 보는 것.(다 해본다!)
infomation Criterion Approach
-> clustering model에 대해 likelihood 를 계산하여 활용.
예) k-means의 경우 GMM 활용하여 계산.
2) cluster중심 위치 '초기값' 설정.
k-means는 cluster 중심 위치 '초기값'을 어떻게
두느냐에 따라 결과값이 달라지기 때문에
잘못하면 엉터리 결과가 나올 수 있다.
-> 이것또한 다양한 연구가 나오고 있다.
3) 구형이 아닌 cluster
normal한 구형이 아닌 cluster를 찾을 때에는 부적절하다.
4) Outlier에 취약
-> 전처리 및 k-medoids 알고리즘으로 해결,
k-medoids : mean을 계산하지 않고,
데이터 중에서 하나를 중심으로 사용.
5) 계산 복잡성
- O(n)으로 hiararchical clutstering와 비교해 무겁지 않다.
'Big Data > ML' 카테고리의 다른 글
| Marginalize (0) | 2019.06.01 |
|---|---|
| KNN Algorithms ( 최근접 이웃 알고리즘) (0) | 2019.05.31 |
| Support Vector Machine . (0) | 2019.05.11 |
| Artificial Neural Networks (0) | 2019.04.16 |
| Deep Learning intro - Perceptron (0) | 2019.04.16 |



