
nathan_H
HDFS Architecture 본문
HDFS 설계에 대해
추상적으로 글로만 설명을 했는데
이번에는 다양한 그림과 함께
HDFS가 어떻게 설계되어져 있고
파일들을 어떻게 읽고 저장하고 요청하는지
알아보고자 한다.
블록 구조 파일 시스템
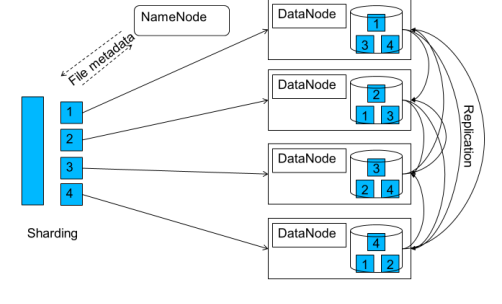
위에 그림 처럼 HDFS는
파일을 블록 구조를 통해 관리 및 분배를 진행을 한다.
기본 블록 크기는 하둡 1.0 : 64MB, 2.0 : 128MB 로 되어져 있고.
블록 구조 파일 시스템을 통해
1. 데이터 위치 찾는 시간 감소
2. 데이터 고나리 정보 크기 감소
효과를 가져오게 된다.
NameNode와 DataNode
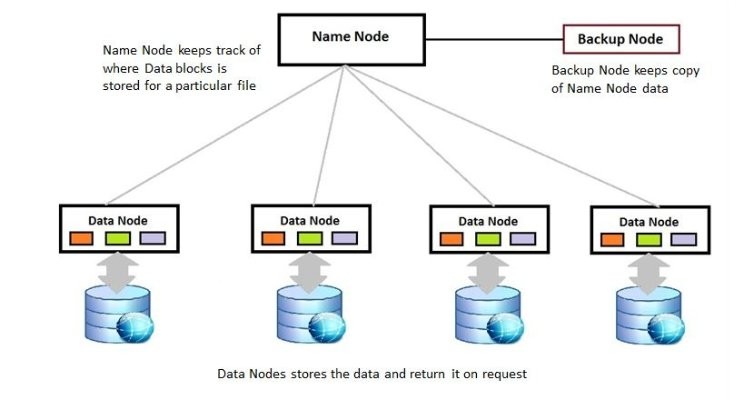
HDFS는 크게 NameNode와 DataNode로 구성되어 있고
NameNode는 수시로 데이터 노드 상태를 모니터링하고
DataNode는 NameNode에게 하트비트를 전송해
주기적으로 송신한다.
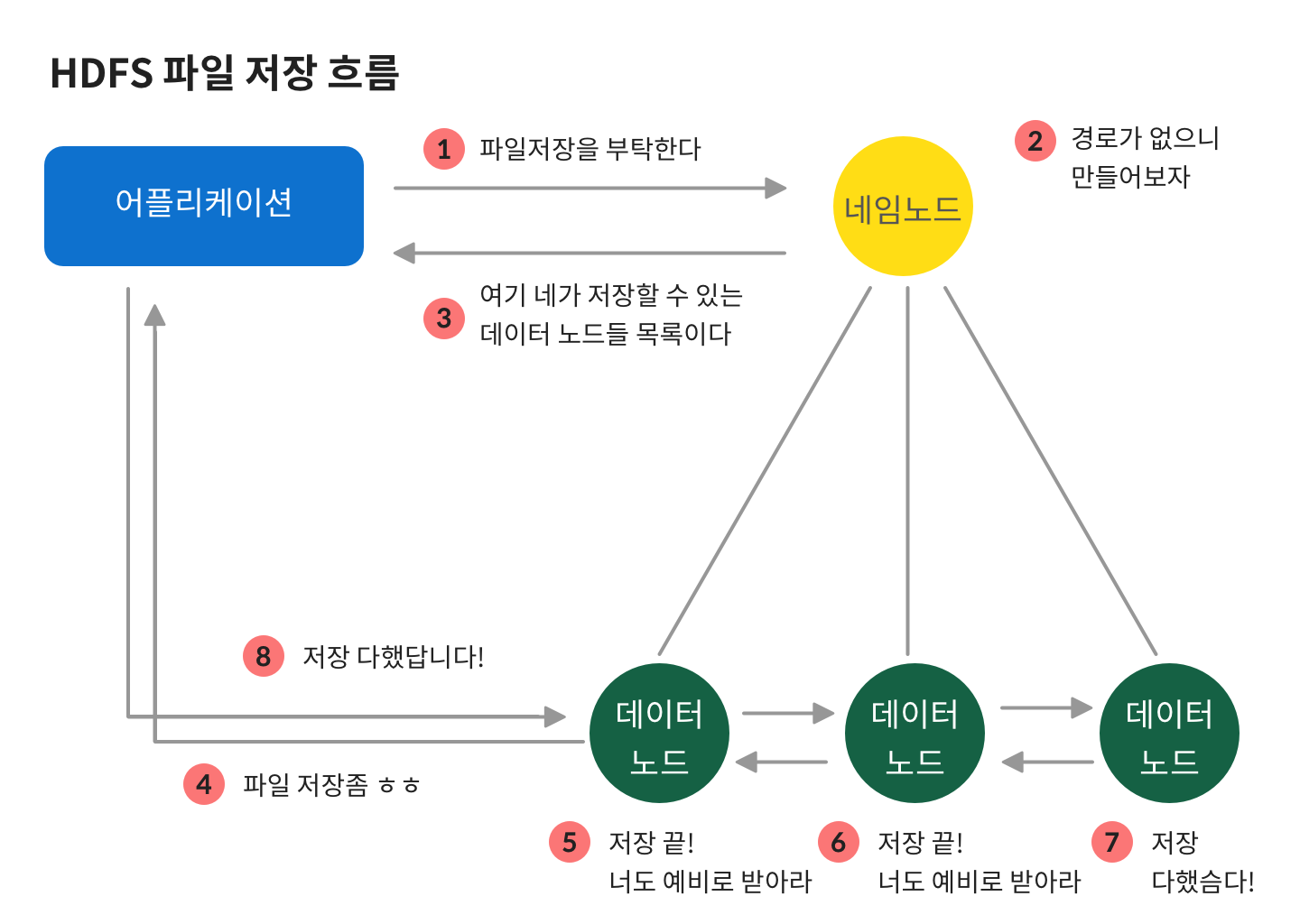
파일 저장
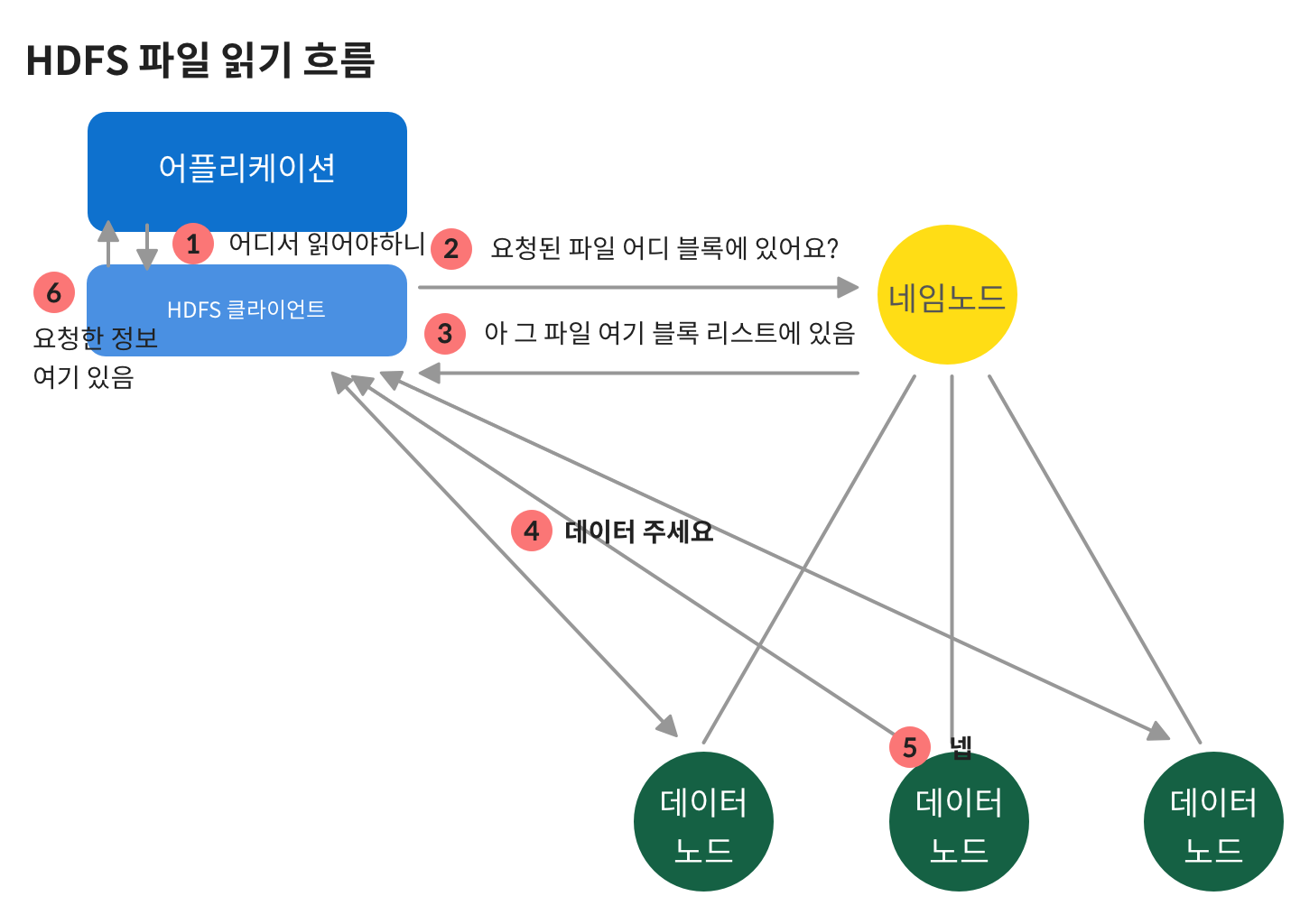
파일 읽기
HDFS 명령어
HDFS를 사용하기 위한 명령어에 대해
몇가지 소개하고자 한다.
사용법
cd hadoop-1.2.1
./bin/hadoop fs -명령어
명령어 List
1. 파일 목록 보기
fs -ls
- 지정한 디렉토리에 파일 정보 출력
fs -lsr
-- 지정한 하위 디렉토리에 파일 정보까지 출력
2. 파일용량 확인
fs -du
- 지정한 디렉토리나 파일의 사용랑량을 확인, 바이트 단위
fs-dus
- 전체 합계 용량 출력
3. 파일 내용 보기.
fs -cat
fs -text
-zip 형태의 압축된 파일도 가능
3. 디렉토리 생성
fs -mkdir
4. 파일 복사
fs -getmerge
-지정한 경로에 잇는 모든 파일의 내용을 합친 후, 로컬 시스템의 하나의 파일로 복사.
fs -cp
- 목적지로 복사
5. 파일 이동
fs -mv
fs- moveFromLocal
- 지정한 로컬 파일 시스템의 파일 및 디렉토리를 목적지 경로로
복사 한후 소스 경로의 파일은 삭제.
6. 파일 삭제- 지정한 디렉토리에 파일 정보 출력
fs -rm
fs -rmr
- 비어 있지 않은 파일도 삭제.
'Big Data > Hadoop' 카테고리의 다른 글
| MapReduce (0) | 2019.06.12 |
|---|---|
| HDFS란? (Hadoop File System) (1) | 2019.06.12 |
| Hadoop 이란? (0) | 2019.06.12 |


